

題目通り、今回はOCRについて話していこうと思います。ゲームの一部の画面をキャプチャしてその画像から文字を出力する(OCR)機能を入れたツールを作成する際にOCRについていろいろ試したので、それに本記事では書いていこうと思います。
使用したOCRについて
今回はtesseract(テッセラクトと読むらしい)をPythonのライブラリpytesseractを通してOCRしました。(書いてて思ったのですが、「OCRしました」って日本語的にあっているのでしょうか。。?)ほかにもいろいろなOCRツールはありましたが、調べた感じ一番スタンダードな感じがしたので、今回はこれを使用します。
今回試したパターン
今回は以下のパターンを試しました。画像処理の知見がほぼ0の状態なのでChatGPTにいろいろアドバイスをもらいながらいくつかのパターンに分けてOCRしました。これらのパターンについて詳しく書いていきたいと思います。
- ゲームの画像をそのままOCR
- ゲームの画像を編集してからOCR(いくつかパターンあり)
- ChatGPTに聞いてみた
ゲームの画像をそのままOCR
このパターンはほんと言葉のままでゲームの画像をキャプチャして、Pythonで画像を読み取りtesseractを使用してOCRするというものです。以下がその時のコードです。
from PIL import Image
import pytesseract
# Windowsの場合、Tesseractのインストールパスを明示する必要があるかもしれません
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 画像を開く
image = Image.open('input.png')
# 文字を抽出
text = pytesseract.image_to_string(image, lang='jpn') # 日本語の場合
# 結果を出力
print(text)
入力した画像が以下です。(ドラゴンクエスト10のゲーム画面の一部)

以下が出力結果
銅 の 木 エ 刀 の 納品 。 レフ
銅 の 鍛冶 ンマ ー の 納品
鋼 の 錬 金 ウ ボ の 納品
鉄 の 鍛治 / ツ マー の 納品
プラ チ ナ 木工 刀 の 納品
プラ チ ナ 鍛冶 ハン マ の 納品微妙にあってたりあってなかったり。。まあ何も前処理とかしてないしこんなもんですよ。。
ゲームの画像を編集してからOCR(いくつかパターンあり)
次はOCRする前に画像を編集して文字を読み取りやすくします。そうすることで精度が上がるらしい。。画像の編集にもいくつか種類があるらしいので、いろいろ試してみました。まずは、画像のグレースケール化を試してみます。コードは以下です。
import cv2
import pytesseract
# Tesseractのパス(Windows環境の場合は必要に応じて)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 画像を読み込み
image = cv2.imread('input.png')
# グレースケール化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# グレースケール画像を保存
cv2.imwrite('grayscale_image.png', gray)
# OCR(日本語)
text = pytesseract.image_to_string(gray, lang='jpn')
# 結果を表示
print(text)
出力結果はこちら。
銅 の さい ほう 針 の 納品
銅 の 木 エ 刀 の 納品
銅 の 欠 治 ハン マー の 納品
銅 の 鯨 金 ツ ボ の 納品
鉄 の 欠 治 刀 シ マー の 納品
銀 の 鐘 金 ラン プ の 納品
銀 の 錬 金 ツ ボ の 納品
プラ チ ナ 木 エ 刀 の 納品
プラ チ ナ 組 冶 ハン マ の 納品先ほどのに比べたらだいぶましになったのではないでしょうか!?
実際に編集した後の画像は以下になります。

では次はグレースケール化に加えてノイズ除去を試してみます。コードは以下です。
import cv2
import pytesseract
# Tesseractのパス(Windowsの場合)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 画像を読み込み
image = cv2.imread('input.png')
# グレースケール化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# ノイズ除去(ガウシアンブラー)
denoised = cv2.GaussianBlur(gray, (5, 5), 0)
# 処理済み画像を保存
cv2.imwrite('grayscale_denoised.png', denoised)
# OCR(日本語)
text = pytesseract.image_to_string(denoised, lang='jpn')
# 結果を出力
print(text)
出力結果はこちら。
抽 の さい ほう 計 の 短 品
抽 の 木 エ ガ の 請 品
級 の 線 金 ツボ の 結 品
プラ チ ナ 木工 刀 の 納品
プラ チ ナ 議 治 ハン マ の 縛 品あれ?先ほどより悪くなってる??
実際に編集した後の画像は以下になります。

ならさらにさらに画像の前処理を加えちゃいましょう!2値化も加えて試してみましょう!コードは以下です。
import cv2
import pytesseract
# Tesseractのパス(Windowsの場合)
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 画像を読み込み
image = cv2.imread('input.png')
# グレースケール化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# ノイズ除去(ガウシアンブラー)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
# 2値化(大津の二値化)
_, thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 処理後の画像を保存
cv2.imwrite('processed_image.png', thresh) # 例: PNG形式で保存
# OCR(日本語)
text = pytesseract.image_to_string(thresh, lang='jpn')
# 結果出力
print(text)
ここまでやったらきっときれいに。。。
貞 の さい ほう 計 の 請 品
肌 の ネエ ガ の 請 品
旧 の 表 金 ツボ の 納品
プラ チ ナ ネエ 刀 の 縛 品
プラ う チ ナ 冶 ハン マ の 張なんかひどくなってる。。?実際に編集した後の画像は以下。

うーんなるほど?なんか漢字がつぶれてたり、真ん中あたりが真っ白になってたりしてますね。。前処理はたくさんすればするほどいいなんてことはないんですね。世の中ちょうどよいのが一番です。
tesseractを使用した中の結果としては画像の前処理をグレースケール化だけしたものが一番でしたね。ただ、今回の画像ではそれが一番相性が良かっただけで、他画像はまた別の結果になる気がしてます。
ChatGPTに聞いてみた
では最後です。ChatGPTに聞いてみましょう!モデルはGPT-4-turboです。(ChatGPT本人に聞きましたw)以下が聞いた時の画像になります。
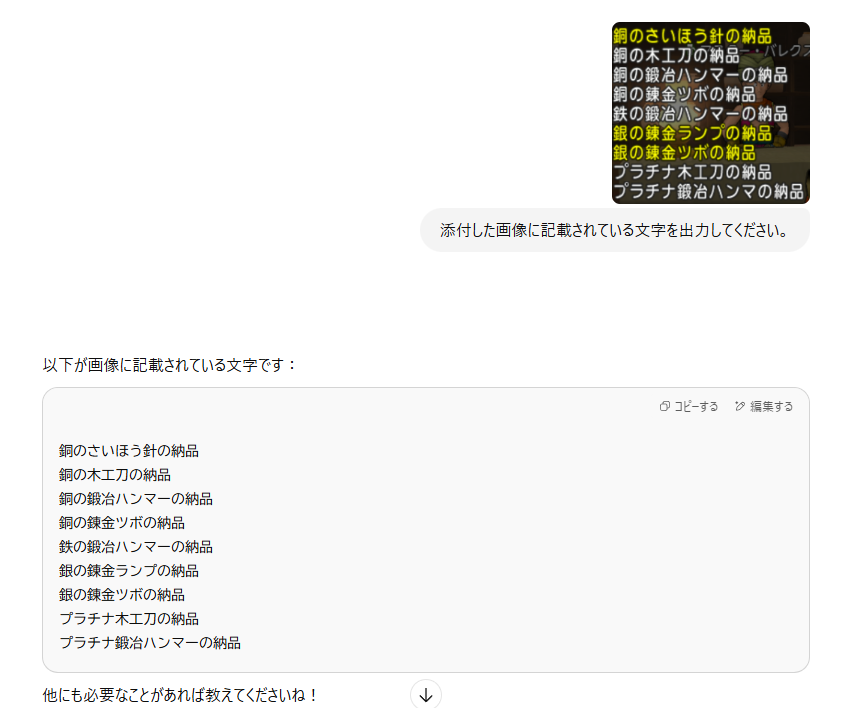
いや完璧。。。
常日頃ChatGPTにはお世話になっていますが、まさか画像認識でもお世話になるとは。。。
おわりに
ここまで見ていただきありがとうございました。今回はOCRにおいてtesseractとOpenAI「GPT-4-turbo」の対決を見ていただきました。さすがと言わんばかりのOpenAI「GPT-4-turbo」の圧勝でしたね。今回の検証を参考にOCR機能を持つツールの作成に励みたいと思います。そのツールについても完成したら記事にして紹介しようかなと思います。これからもchike-techをよろしくお願いいたします!

コメント